
How SGLang Saved Me Days of Time
It's damn fast 🚀

A few weeks ago, I found myself looking for a fast LLM inference tool to run some experiments for an ICML deadline. I had heard about TGI and vLLM but never really tried them. A quick inspection of the two lead me to try out vLLM as benchmarks seemed to indicate that it is far superior to whatever exists out there -
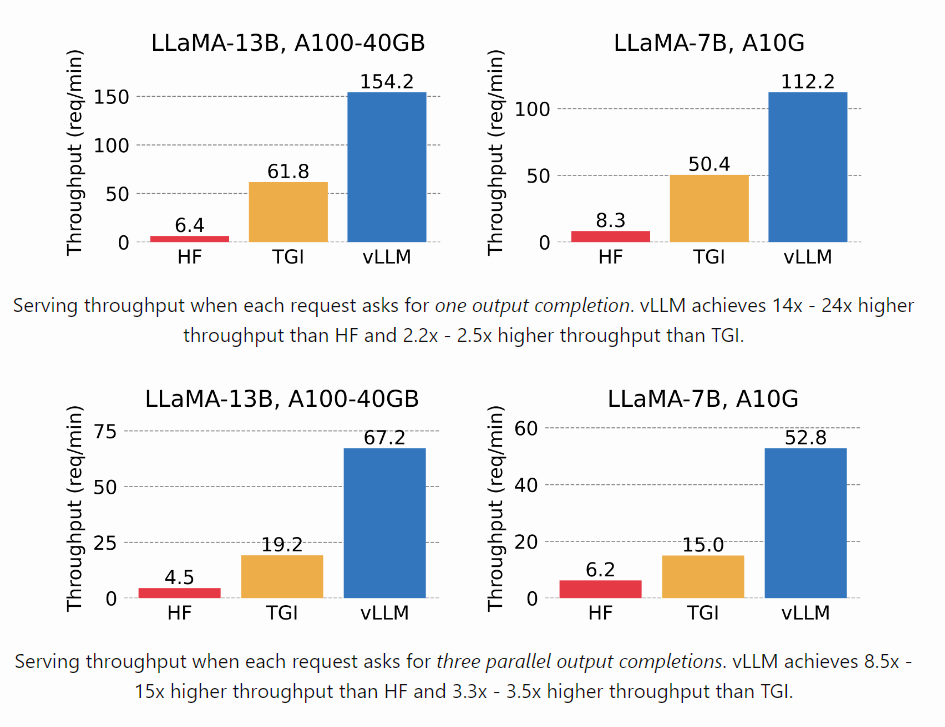
vLLM gave me really good speedups for one of the three experiments. It made it feasible to run it at scale across multiple models and datasets. However, even though there were considerable speedups in the other two experiments it was nowhere close to what would make it sustainable to run at scale.
Enter SGLang (Structured Generation Language for LLMs), which in the words of its creators is “a structured generation language designed for large language models (LLMs).” I was a bit skeptical going into using it for the first time, but it did NOT disappoint me 😉. As a sidenote a lot of people working on SGLang are also the same people who built vLLM. I’m really thankful to them for building such cool software and making it available for everyone to use. I’d also like to thank Lianmin Zheng for helping out by quickly creating an interface for my use case. You can find the discussion thread here.
Let’s now dive into how SGLang saved me from spending days running these experiments.
I needed to run inference to get generation log probabilities of around 70K sequences. These sequences can be binned into groups of size 100 where the prefix is the same but the suffixes are different. I needed the log probabilities of these different suffixes to choose the suffix with the highest probability amongst all choices. Experiment 1 gained good boosts from vLLM and so did experiment 2 & 3. vLLM however does not manage complex KV caching patterns unlike SGLang -
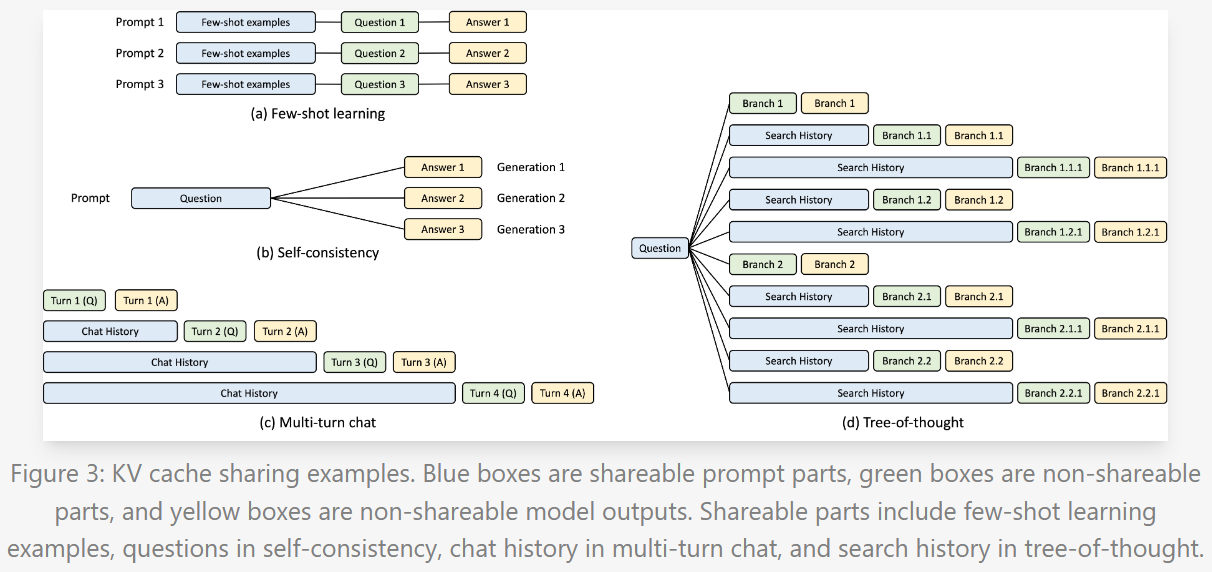
Hence when the prefix has some common and some not common portions, vLLM caching is of little help. This is where SGLang significantly outperforms vLLM and smartly figures out what parts of the KV cache can be reused. This is enabled by their use of RadixAttention. I won’t delve deep into it, but it based on the popular radix tree data structure. At a high level past KV cache values are retained in a radix tree and allows for efficient prefix searches, insertions and evictions based on a LRU policy. It is a super interesting concept, and I would recommend reading up more on it here - Fast and Expressive LLM Inference with RadixAttention and SGLang
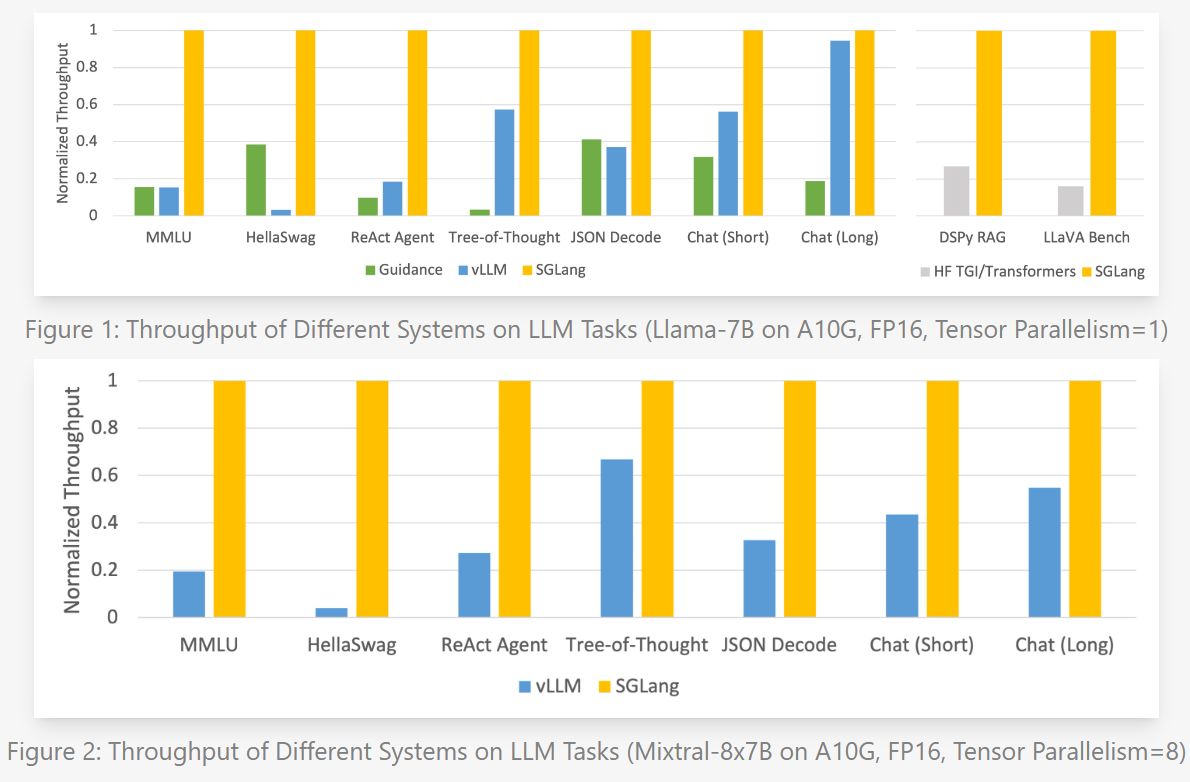
Some benchmarks are shown below -
Now with everything else out of the way. Here’s a code sample adapted from the official tutorial -
Run the server -
python -m sglang.launch_server --model-path "model_path" --port 30000 --tp 2model_path is to be replaced with the path of the model in your file system, the port is where your API calls will hit and the tp flag allows you to use tensor parallelism over 2 GPUs.
Now you can make calls to the server -
import sglang as sgl
@sgl.function
def tool_use(s, question):
s += "To answer this question: " + question + ", "
s += "I need to use a " + sgl.gen("tool", choices=["calculator", "search engine"])
def main():
questions = [
"What is 5 + 6?",
"Who is Michael Jordan?",
]
states = tool_use.run_batch([{"question": q} for q in questions])
for question, state in zip(questions, states):
print("questions:", question)
print("choice:", state["tool"])
meta_info = state.get_meta_info("tool")
print("logprobs of choice 1", meta_info["prompt_logprob"][0])
print("logprobs of choice 2", meta_info["prompt_logprob"][1])
print('-' * 50)
if __name__ == "__main__":
sgl.set_default_backend(sgl.RuntimeEndpoint("http://localhost:30000"))
main()Now you might ask me, what the heck is happening? Let’s think step-by-step like good LLMs 😏
@sgl.function
def tool_use(s, question):
s += "To answer this question: " + question + ", "
s += "I need to use a " + sgl.gen("tool", choices=["calculator", "search engine"])The sgl.function decorator is necessary to use different prompt flows made available within SGLang.
You can think of the parameter s as an empty string where you add in more stuff. This also allows SGLang to figure out what parts are going to be common.
Now the following line sgl.gen("tool", choices=["calculator", "search engine"]) allows you to define a name to give to the output and later access it by (called tools here) and compute the log probs for the choices given.
Finally, you can do something like tool_use.run_batch which does several under the hood optimizations to run inference over a batch and return the log probs for the different choices for all the examples. You can then access the different results by some indexing as shown in the example.
Now enough showering praises, was everything smooth sailing? No!
I faced my fair share of issues which is to be expected given the library is still in its early phases. Some of the issues I faced are -
Limited model support: A lot of models are not yet supported, some notables ones being Pythia and Falcon. However, as I can judge by the development pace, several of them will be added soon and you can also contribute one if you want!
Server startup sometimes fails for larger models: Sometimes the model loading finishes, but the server does not startup. There is a hacky fix for this. I noticed that this happened for models which took long to load, and an easy fix is let this error happen once. Once the model is loaded, there seems to be some caching which is done which make the model load very fast the next time avoiding the error.
It’s not always convenient to use a server. There is an option to define a runtime within your script but that didn’t really work out for me but I’m optimistic that it would be fixed soon or there’s probably an issue on my end.
Overall, I’m really happy with the results I got, the speed I achieved and that such a tool is available for everyone to use!
Btw I’m on the lookout for new gigs. If this kind of stuff interests you and you are hiring/want to collaborate, do reach out to me on Twitter. Find more about me here.